Apache Kafka GETTING STARTED
kafka 1.0 기준으로 작성 했습니다.
Apache Kafka®는 분산 형 스트리밍 플랫폼 입니다. 그게 정확히 무슨 뜻입니까?
아파치 카프카는 분산 스트리밍 플랫폼입니다.
우리는 스트리밍 플랫폼이 세 가지 핵심 기능을 가지고 있다고 생각합니다.
- 메시지 대기열 또는 엔터프라이즈 메시징 시스템과 유사 이를 통해 레코드 스트림을 게시하고 구독 할 수 있습니다.
- 내결함성있는 방식으로 레코드 스트림을 저장할 수 있습니다.
- 발생하는 레코드 스트림을 처리 할 수 있습니다.
카프카는 무엇에 좋은가? 그것은 두 가지 광범위한 응용 프로그램에 사용됩니다.
- 시스템 또는 응용 프로그램간에 데이터를 안정적으로 얻는 실시간 스트리밍 데이터 파이프 라인 구축
- 데이터 스트림을 변환하거나 이에 반응하는 실시간 스트리밍 애플리케이션 구축
카프카가 이러한 일을 어떻게하는지 이해하려면 카프카의 기능을 아래에서 위로 탐구 해 봅시다.
처음 몇 가지 개념 :
- Kafka는 하나 이상의 서버에서 클러스터로 실행됩니다.
- 카프카 클러스터는 topic 라는 카테고리 에 레코드 스트림을 저장 합니다 .
- 각 레코드는 키, 값 및 타임 스탬프로 구성됩니다.
Kafka는 4 가지 핵심 API를 제공합니다.
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
Kafka에서 클라이언트와 서버 간의 통신은 단순하고 고성능의 언어에 구애받지 않는 TCP 프로토콜로 수행 됩니다. 이 프로토콜은 버전이 지정되며 이전 버전과의 하위 호환성을 유지합니다. 우리는 카프카를위한 자바 클라이언트를 제공하지만 클라이언트는 여러 언어로 제공됩니다 .
Topics and Logs
먼저 Kafka가 제공하는 핵심 추상화에 대해 알아 봅시다.
topic는 레코드가 공개되는 카테고리 또는 피드 이름입니다. 카프카의 topic는 항상 multi-subscriber 입니다. 즉, topic에는 작성된 데이터를 구독하는 0, 1 또는 많은 사용자가있을 수 있습니다.
각 topic에 대해 Kafka 클러스터는 다음과 같은 partitions 로그를 유지합니다.
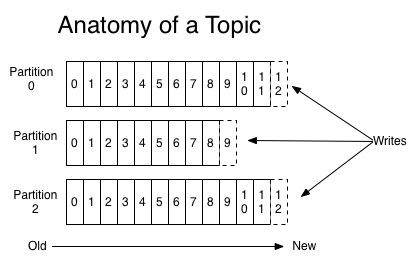
각 partitions은 계속해서 추가되는 순서화 된 불변의 레코드 순서 인 구조화 된 커밋 로그입니다. partitions의 레코드에는 partitions 내의 각 레코드를 고유하게 식별 하는 offset 이라는 순차적 인 ID 번호가 각각 지정 됩니다.
Kafka 클러스터는 구성 가능한 보존 기간을 사용하여 게시 된 모든 레코드 (소비 여부에 관계없이)를 보유합니다. 예를 들어 보존 정책을 2 일로 설정하면 레코드를 게시 한 후 2 일 동안 소비 정책을 사용할 수 있으며 그 이후에는 사용 가능한 공간을 늘리기 위해 폐기됩니다. Kafka의 성능은 데이터 크기와 관련하여 사실상 일정하므로 데이터를 오랫동안 저장하는 것은 문제가되지 않습니다.
실제로, consumer 기준으로 유지되는 유일한 메타 데이터는 로그에서 해당 consumer의 offset 또는 위치입니다. 이 offset은 consumer가 제어합니다. 일반적으로 consumer는 레코드를 읽을 때 선형 적으로 offset을 진행하지만 실제로는 위치가 consumer에 의해 제어되므로 좋아하는 순서대로 레코드를 소비 할 수 있습니다. 예를 들어, consumer는 과거의 데이터를 다시 처리하기 위해 오래된 offset으로 재설정하거나 가장 최근의 레코드로 건너 뛰고 “지금”에서 소비하기 시작할 수 있습니다.
이러한 기능의 결합은 Kafka consumer가 매우 저렴하다는 것을 의미합니다. 클러스터 또는 다른 consumer에게 큰 영향을 미치지 않고 출퇴근 할 수 있습니다. 예를 들어, 커맨드 라인 도구를 사용하여 기존 consumer가 소비 한 것을 변경하지 않고도 topic의 내용을 “꼬리”수 있습니다.
로그의 partitions은 여러 가지 용도로 사용됩니다. 첫째, 로그를 단일 서버에 맞는 크기 이상으로 확장 할 수 있습니다. 각 개별 partitions은 호스트하는 서버에 적합해야하지만 topic에 많은 partitions이있어 임의의 양의 데이터를 처리 할 수 있습니다. 둘째, 그들은 병렬 처리의 단위처럼 행동합니다.
Distribution
로그의 partitions은 Kafka 클러스터의 서버를 통해 배포되며 각 서버는 데이터를 처리하고 partitions 공유에 대한 요청을 처리합니다. 각 partitions은 장애 허용을 위해 구성 가능한 수의 서버에 복제됩니다.
각 partitions에는 “leader”역할을하는 서버와 “followers”역할을하는 0 이상의 서버가 있습니다. leader는 followers가 leader를 수동적으로 복제하는 동안 partitions에 대한 모든 읽기 및 쓰기 요청을 처리합니다. leader가 실패하면 추종자 중 하나가 자동으로 새로운 leader가됩니다. 각 서버는 일부 partitions의 leader와 다른 서버의 팔로어로 작동하므로로드가 클러스터 내에서 잘 균형을 이룹니다.
Producers
Producers는 선택한 topic에 데이터를 게시합니다. Producers는 topic 내에서 어떤 partitions에 할당 할 레코드를 선택해야합니다. 이는로드 균형을 맞추기 위해 라운드 로빈 방식으로 수행되거나 일부 의미 적 partitions 함수 (레코드의 일부 키를 기반으로 함)에 따라 수행 될 수 있습니다. 두 번째로 파티셔닝을 더 많이 사용합니다!
Consumers
Consumers는 consumer groups 이름을 사용하여 자신에게 레이블 을 지정하고 topic에 게시 된 각 레코드는 각 구독 consumer groups 내의 하나의 consumer 인스턴스에 전달됩니다. consumer 인스턴스는 별도의 프로세스 또는 별도의 시스템에있을 수 있습니다.
모든 consumer 인스턴스가 동일한 consumer groups을 갖는 경우 레코드는 consumer 인스턴스보다 효과적으로 로드 밸런싱됩니다.
모든 consumer 인스턴스가 서로 다른 consumer groups을 갖고 있으면 각 레코드가 모든 consumer 프로세스에 브로드 캐스팅됩니다.
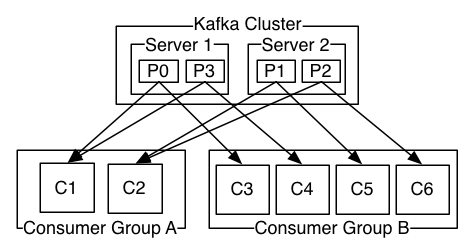
2 개의 consumer groups이있는 4 개의 partitions (P0-P3)을 호스팅하는 2 대의 서버 Kafka 클러스터. consumer groups A에는 두 개의 consumer 인스턴스가 있고 그룹 B에는 네 개의 인스턴스가 있습니다.
그러나 더 일반적으로, 우리는 topic가 각각의 “logical subscriber”에 대해 하나씩 적은 수의 consumer groups을 갖는 것을 발견했습니다. 각 그룹은 확장 성 및 내결함성을위한 많은 consumer 인스턴스로 구성됩니다. 구독자가 단일 프로세스 대신 consumer 클러스터 인 publish-subscribe 의미론에 불과합니다.
카프카에서 소비가 구현되는 방식은 로그의 partitions을 consumer 인스턴스로 나누어 각 인스턴스가 어느 시점에서든 partitions의 “공정한 분배”를 독점적으로 사용하는 것입니다. 이 그룹 구성원을 유지하는이 과정은 Kafka 프로토콜에 의해 동적으로 처리됩니다. 새 인스턴스가 그룹에 참여하면 그룹의 다른 구성원으로부터 일부 partitions을 인계받습니다. 인스턴스가 종료되면 해당 partitions이 나머지 인스턴스에 배포됩니다.
카프카 는 한 topic의 다른 partitions 사이가 아니라 한 partitions 내의 레코드에 대해서만 전체 주문을 제공합니다 . 대부분의 응용 프로그램에서 키 단위로 데이터를 분할하는 기능과 결합 된 분할 단위 별 정렬로 충분합니다. 그러나 레코드 전체 순서가 필요한 경우 이는 하나의 partitions 만있는 항목으로 수행 할 수 있습니다. 단, 이는 consumer groups당 하나의 consumer 프로세스를 의미합니다.
Guarantees
high-level Kafka에서는 다음과 같은 보장을합니다 :
- 생산자가 특정 주제 파티션으로 보낸 메시지는 전송 된 순서대로 추가됩니다. 즉, 레코드 M1이 레코드 M2와 동일한 생성자에 의해 보내지고 M1이 먼저 보내지면 M1은 M2보다 더 낮은 오프셋을 가지며 로그에서 더 일찍 나타납니다.
- 소비자 인스턴스는 로그에 저장된 순서대로 레코드를 봅니다.
- 복제 인수 N이있는 항목의 경우 로그에 커밋 된 레코드를 손실하지 않고 최대 N-1 개의 서버 오류를 허용합니다.
이러한 보증에 대한 자세한 내용은 설명서의 디자인 섹션에 나와 있습니다.
Kafka as a Messaging System
카프카의 스트림 개념은 기존 엔터프라이즈 메시징 시스템과 어떻게 비교 되는가?
메시징은 전통적으로 두 가지 모델을 가지고 있습니다 : queuing 및 publish-subscribe. queue에서 consumer 풀은 서버에서 읽을 수 있으며 각 레코드는 그 중 하나에 저장됩니다. publish-subscribe에서 레코드는 모든 소비자에게 브로드 캐스팅됩니다. 이 두 모델은 각각 강점과 약점을 가지고 있습니다. 대기열 처리 기능을 사용하면 여러 소비자 인스턴스에서 데이터 처리를 나눌 수 있으므로 처리 규모를 확장 할 수 있습니다. 유감스럽게도 대기열은 다중 구독자가 아닙니다. 한 프로세스가 사라진 데이터를 읽으면 대기열이 여러 구독자가 아닙니다. Publish-subscribe는 여러 프로세스에 데이터를 브로드 캐스트 할 수 있지만 모든 메시지가 모든 구독자에게 전달되므로 처리를 조정할 방법이 없습니다.
카프 카의 소비자 그룹 개념은이 두 개념을 일반화합니다. 대기열에서와 마찬가지로 소비자 그룹은 프로세스 모음 (소비자 그룹의 구성원)을 통해 처리를 나눌 수 있습니다. publish-subscribe와 마찬가지로 Kafka를 사용하면 여러 소비자 그룹에 메시지를 브로드 캐스트 할 수 있습니다.
카프카의 모델의 장점은 모든 주제가 이러한 속성을 모두 갖추고 있다는 것입니다. 즉, 처리 규모를 조정할 수 있고 다중 가입자이기도하므로 둘 중 하나를 선택할 필요가 없습니다.
Kafka는 전통적인 메시징 시스템보다 강력한 주문 보증을 제공합니다.
전통적인 큐는 서버에서 순서대로 레코드를 보유하고, 여러 소비자가 큐에서 소모하는 경우 서버는 저장된 순서대로 레코드를 전달합니다. 그러나 서버가 레코드를 순서대로 전달하더라도 레코드는 비동기 적으로 소비자에게 전달되므로 서로 다른 소비자에게 순서가 잘못 될 수 있습니다. 이것은 사실상 병렬 소비가 발생하면 레코드의 순서가 손실된다는 것을 의미합니다. 메시징 시스템은 대기열에서 하나의 프로세스 만 사용할 수있는 “독점적 인 소비자”라는 개념을 사용하여이 문제를 해결하기도하지만 처리 과정에서 병렬 처리가 없다는 것을 의미합니다.
카프카는 더 잘합니다. 주제 내에서 병렬 처리 개념 (파티션)을 가짐으로써 카프카는 소비자 프로세스 풀에 대해 주문 보증과로드 밸런싱을 모두 제공 할 수 있습니다. 이는 주제의 파티션을 소비자 그룹의 소비자에게 할당하여 각 파티션이 그룹의 정확히 한 소비자에 의해 소비되도록하여 수행됩니다. 이렇게하면 소비자가 해당 파티션의 유일한 독자이고 순서대로 데이터를 사용하게됩니다. 파티션이 많으므로 많은 소비자 인스턴스에서로드의 균형을 유지합니다. 그러나 소비자 그룹에는 파티션보다 더 많은 소비자 인스턴스가있을 수 없습니다.
Kafka as a Storage System
분리 된 공개 메시지가 메시지를 소비하지 못하게하는 메시지 큐는 사실상 메시지의 저장 시스템으로 작동합니다. 카프카가 다른 점은 그것이 매우 훌륭한 저장 시스템이라는 것입니다.
Kafka에 기록 된 데이터는 디스크에 기록되고 내결함성을 위해 복제됩니다. Kafka는 생산자가 서면 승인을 기다릴 수 있도록하여 서면이 완전히 복제되고 서면으로 작성된 서 v가 지속되는 경우에도 서 v가 지속될 때까지 쓰기가 완료된 것으로 간주하지 않도록합니다.
Kafka가 scale well-Kafka를 사용하는 디스크 구조는 서버에 50KB 또는 50TB의 영구 데이터를 가지고 있더라도 동일하게 수행합니다.
스토리지를 중요하게 생각하고 클라이언트가 읽기 위치를 제어 할 수있게 된 결과, Kafka는 고성능, 낮은 대기 시간의 커밋 로그 저장, 복제 및 전달 전용의 일종의 특수 목적의 분산 파일 시스템으로 생각할 수 있습니다.
Kafka의 커밋 로그 저장 및 복제 설계에 대한 자세한 내용은 이 페이지를 참조하십시오.
Kafka for Stream Processing
데이터 스트림을 읽고, 쓰고, 저장하는 것만으로는 충분하지 않습니다. 목적은 스트림의 실시간 처리를 가능하게하는 것입니다.
Kafka에서 스트림 프로세서는 입력 항목에서 연속적인 데이터 스트림을 가져 와서이 입력에 대한 일부 처리를 수행하고 주제를 출력하기 위해 지속적인 데이터 스트림을 생성하는 모든 것입니다.
예를 들어, 소매 응용 프로그램은 판매 및 출하의 입력 스트림을 받아 들여이 데이터에서 계산 된 재주문 및 가격 조정 스트림을 출력 할 수 있습니다.
생산자 API와 소비자 API를 사용하여 직접 간단한 처리를 수행 할 수 있습니다. 그러나보다 복잡한 변환의 경우 Kafka는 완전히 통합 된 Streams API를 제공합니다 . 따라서 스트림에서 집계를 계산하거나 스트림을 함께 결합하는 중요하지 않은 처리를하는 응용 프로그램을 작성할 수 있습니다.
이 기능은이 유형의 애플리케이션이 직면 한 어려운 문제를 해결하는 데 도움이됩니다. 즉, 순서가 잘못된 데이터 처리, 코드 변경 사항으로 입력 재 처리, 상태 계산 등입니다.
스트림 API는 Kafka가 제공하는 핵심 기본 요소를 기반으로합니다. 입력에 생산자 및 소비자 API를 사용하고 상태 저장을 위해 Kafka를 사용하며 스트림 프로세서 인스턴스 간의 내결함성을 위해 동일한 그룹 메커니즘을 사용합니다.
Putting the Pieces Together
메시징, 스토리지 및 스트림 처리의 이러한 결합은 드문 것처럼 보일 수 있지만 스트리밍 플랫폼으로서의 카프카의 역할에 필수적입니다.
HDFS와 같은 분산 파일 시스템을 사용하면 일괄 처리를 위해 정적 파일을 저장할 수 있습니다. 사실상 이와 같은 시스템을 사용하면 과거의 기록 데이터를 저장하고 처리 할 수 있습니다 .
기존 엔터프라이즈 메시징 시스템을 사용하면 가입 한 후에 도착할 향후 메시지를 처리 할 수 있습니다. 이런 식으로 작성된 응용 프로그램은 도착하는대로 미래의 데이터를 처리합니다.
Kafka는이 두 가지 기능을 모두 갖추고 있으며 스트리밍 응용 프로그램과 스트리밍 데이터 파이프 라인의 플랫폼으로 Kafka를 사용하는 데있어이 두 가지 기능이 모두 중요합니다.
스토리지 및 대기 시간이 짧은 구독을 결합하여 스트리밍 응용 프로그램은 과거 및 미래 데이터를 동일한 방식으로 처리 할 수 있습니다. 즉, 단일 응용 프로그램에서 기록 된 저장된 데이터를 처리 할 수 있지만 마지막 레코드에 도달 할 때 종료하는 것이 아니라 향후 데이터가 도착할 때 처리를 유지할 수 있습니다. 이는 메시지 처리 응용 프로그램뿐만 아니라 일괄 처리를 포함하는 스트림 처리의 일반화 된 개념입니다.
마찬가지로 스트리밍 데이터 파이프 라인의 경우 실시간 이벤트에 가입하면 매우 짧은 지연 시간의 파이프 라인에 Kafka를 사용할 수 있습니다. 데이터를 안정적으로 저장하는 기능은 데이터 전달을 보장해야하는 중요한 데이터 또는 주기적으로 데이터를로드하는 오프라인 시스템과의 통합을 위해 사용하거나 유지 관리를 위해 오랜 기간 동안 중단 될 수 있습니다. 스트림 처리 설비는 도착하는대로 데이터를 변환 할 수있게합니다.
Kafka가 제공하는 보증, API 및 기능에 대한 자세한 내용은 나머지 설명서를 참조하십시오 .